
 新站到V网_Xinzhandao.COM
新站到V网_Xinzhandao.COM

近日,ChatGPT的开发公司OpenAI公布了一款名为“Sora”的视频生成模型。Sora模型以其独特的能力,使得通过文本输入就能快速生成长达一分钟的高清视频。这些视频不仅具备多个角色、复杂的场景设置,还能呈现出精确的物理细节和背景信息。无论是熙熙攘攘的街头人群,还是雨后东京的街头漫步,Sora都能以令人难以置信的逼真度将文本描述转化为生动的视觉画面。
以东京街头这段demo为例,如果不仔细查看画面细节,我们第一感受以为该视频来自于真实场景拍摄,而且整个画面的运行均采用了一镜到底的方式进行。然而仔细观察还是可以发现,远处人物的动作细节,以及街道霓虹灯文字会存在错误或者与实际逻辑不符的问题。
")
OpenAI表示,Sora模型的研发初衷是为了让人工智能能够更好地理解和模拟现实世界中的物理运动。通过这一模型,他们希望能够训练AI解决那些需要与现实世界进行互动的问题。虽然目前Sora还存在一些局限性,如可能难以准确模拟复杂场景的物理原理,或者无法完全理解某些因果关系,但这并不妨碍它在数字娱乐市场上产生深远影响。
面对这些关注和质疑,OpenAI表示他们正在与专家团队合作,对Sora模型进行进一步的测试和完善。他们计划密切关注这一模型在各个领域的应用,包括可能出现的错误信息、仇恨内容和偏见等。
 宁夏朝觐报名网登录入口https://w
宁夏朝觐报名网登录入口https://w 石家庄人民政府官网受理查询平台入口111
石家庄人民政府官网受理查询平台入口111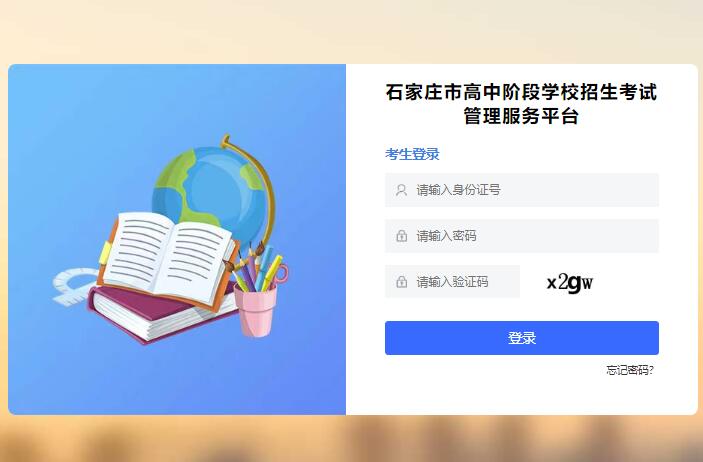 2023年石家庄中考报名系统121.28
2023年石家庄中考报名系统121.28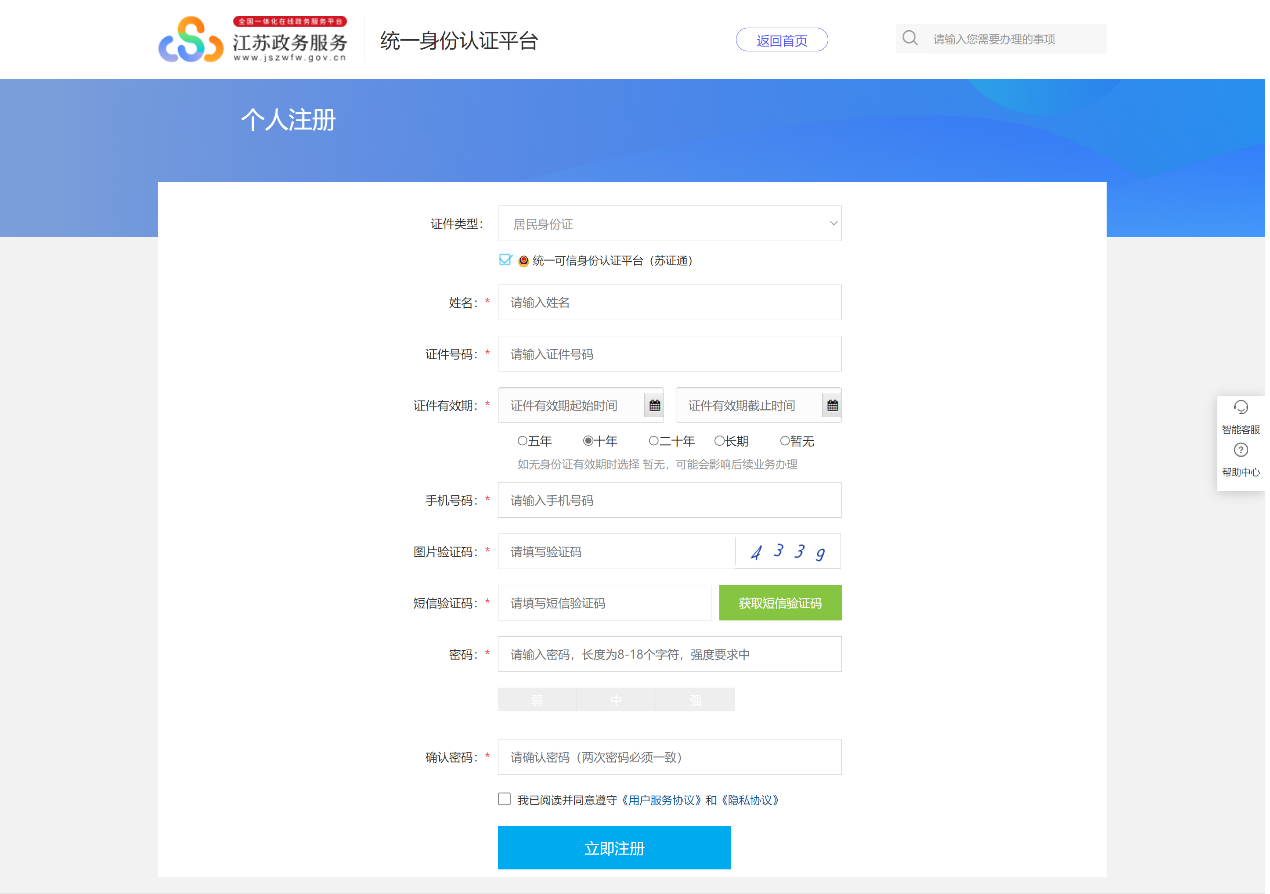 江苏政务服务网统一身份认证系统www.j
江苏政务服务网统一身份认证系统www.j 文心一言官网yiyan.baidu.co
文心一言官网yiyan.baidu.co 温州英特流向信息查询系统www.wzme
温州英特流向信息查询系统www.wzme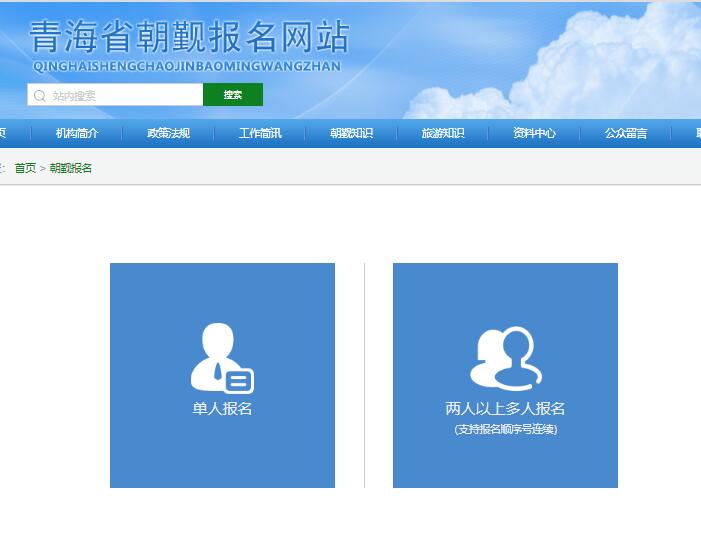 青海省朝觐报名网站登录入口http://
青海省朝觐报名网站登录入口http://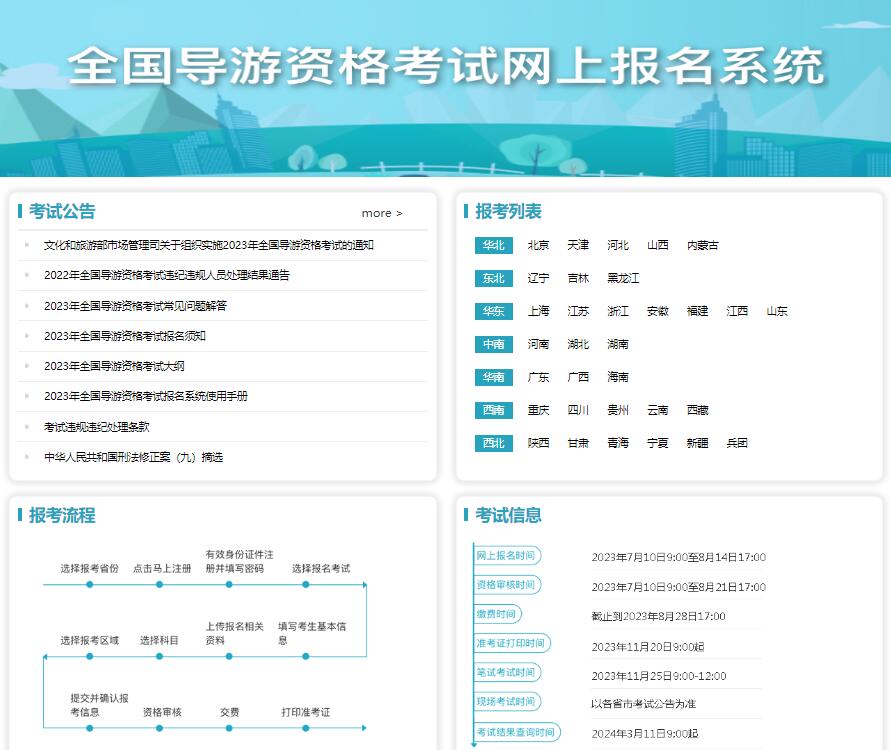 2023年全国导游资格考试网上报名系统m
2023年全国导游资格考试网上报名系统m